
Making GTA 3 Look Like GTA 5 with CycleGAN
CycleGAN is a type of General Adversarial Neural Network for image to image translation. This involes taking images that belong to one domain and translating them to another. Now what do I mean by domain? In this case, a domain is a general category to which an image can belong. An example of a domain could be a set of landscape photos that were taken in the summer time. Another example of another domain could be set of landscape photos that were taken in the winter time. CycleGAN would allow us to translate the images taken in the summer to look as if they were taken in the winter. This is pretty powerful and can have some pretty interesting applications, especially for generative art.
Some other examples are translating images of horses to look like
zebras
 or Monet paintings to look like
photographs
or Monet paintings to look like
photographs
 .
There are even more creative applications of this
here.
.
There are even more creative applications of this
here.
Image to image translation may sound familiar to another techniquen known as neural style transfer.

This idea is closely related to image to image translation, but is more generally related to taking textures and styles from one single image, known as the style image, and applying it to another image, known as the content image. The key here is the fact that it deals with the transfer of “style” from one particular image to another. This “style” tends to involve features that are more coarse and are applied to the entire content image without discriminating between objects of interest. Image to image translation is concerned with the more general problem of not only transferring styles and textures, but specefic pieces of content from image to image. In the horse2zebra example above, notice how only the horse has had zebra stripes transplanted on it. This is indicative of not only style transfer, but also some form of object localization. Image to image translation can involve many tasks (object transfiguration, season transfer, photo enhancement), of which style transfer is one.
The interesting thing about CycleGAN is that it learns to translate images without having pairwise labels to connect the samples between domains. Having pairwise labels in each domain is akin to having labels in supervised learning. You can imagine that in certain instances, this can be very difficult to attain. For example, in the previously mentioned horse2zebra dataset, in order to generate pairwise labels, for each image of a horse, we have to have a corresponding image of the same horse with zebra patterns on it. This can be costly and take quite some fine-grained photoshop work to get just right. Having to generate the corresponding labels for each image may not be practical depending on the domain. CycleGAN allows us to ditch the pairwise labels and learn a mapping from one domain to another only using the knowledge of the domains to which each image belongs. This makes it different from other image to image translation solutions such as Pix2Pix, which rely on pairwise samples in order to generate the mapping from one domain to another.
The lack of pairwise training data also makes training less stable, as we will see in the results.
Scraping the Data
One day, two videos popped up in my YouTube recommendation: a full GTA 3 gameplay and a full GTA 5 gameplay video. I began by posing the question - What would GTA 3 look like if it had been developed a decade later, around the timeGTA 5 was released? This then had many other follow-up questions: What would the characters look like? What would the environment look like? Would any of this impact the gameplay? After mulling it over, I realized I could find these answers myself with CycleGAN.
The screenshots from GTA 3 were produced from this thorough gameplay.
The screenshots from GTA 5 were produced from this incredible gameplay.
This article will outline some of the methods and results of using CycleGAN’s image to image translation capabilites to make GTA 3 graphics look like GTA 5.
Before getting into the results, I would like to do a brief review of the main driving concept behind CycleGAN, which is the cycle-consistent loss.
Cycle-consistent Loss
In an image to image translation problem, there are two image domains: X and Y. CycleGAN consists of two generator models: G and F. G learns to map images from Domain X to Y, while F learns to map images from Domain Y to X. For each domain, there is also a discriminator that is responsible for determining how close the samples generated by the generators are to the actual domains they are supposed to represent, denoted as Dx and Dy, respectively.
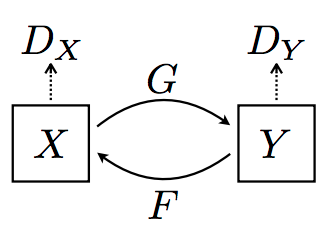
Cycle-consistent loss adds structure to the loss function, stabilizing the learning process for each generator model. This involves having three components in the loss function: the discriminator loss for Dx, the discriminator loss for Dy, and the cycle loss.
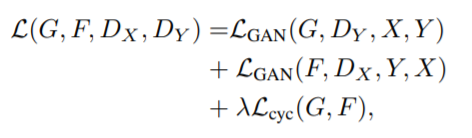
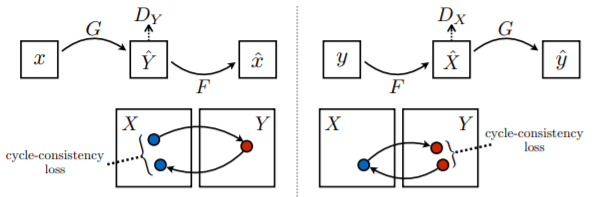
The cycle loss involves creating a new image by using generator G to translate an image from domain X to Y. This new image is then translated back from domain Y to domain X using generator F. This “cycled” image is then compared to the original. This is also repeated the other way around, where the output from generator F is cycled to produce an image from domain Y, which is compared to the original. The differences in the images are used to determine the value of the cycle loss term. Ideally, if we had a perfect model, the cycled image and original should be the same.
Initial model selection
To start the project, I began by using the pix2pix generator and discriminator architectures for both sets of generators and discriminators. These were both architectures that were used in this TensorFlow CycleGAN tutorial and I didn’t have much reason to change them, so that’s where I started. I mainly stuck to the hyper-parameters (learning rate, batch size, loss_weights) used in the tutorial as well.
Initial Results
The images below show the best results produced by CycleGAN.
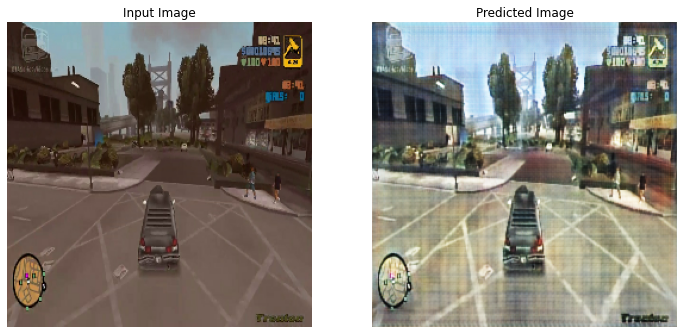
This was produced by training CycleGAN for 100 epochs. The image on the left is a screenshot from GTA 3. The image on the right is the same image converted to look like GTA 5 with CycleGAN. Right off the bat, we can see that the darker colorscheme of GTA 3 is transformed into the much brighter colorscheme of GTA5. The entire image itself has a much higher brightness. The sky, the buildings, and the road all look much brighter, as they may appear in GTA 5. The overall quality of the image, however, is degraded, leaving us with lots of unwanted artifacts. Additionally, certain bright areas appear to too bright, as is exhibited by the sidewalks. With CycleGAN, not only can we translate images from screenshots from GTA 3 to GTA 5, we can also translate from GTA 5 to GTA3. This allows us to subjectively analyze the effectiveness of our models in multiple ways. Below, the image on the left is a screenshot from GTA 5, while the image on the right is the same image transformed to look like GTA 3.
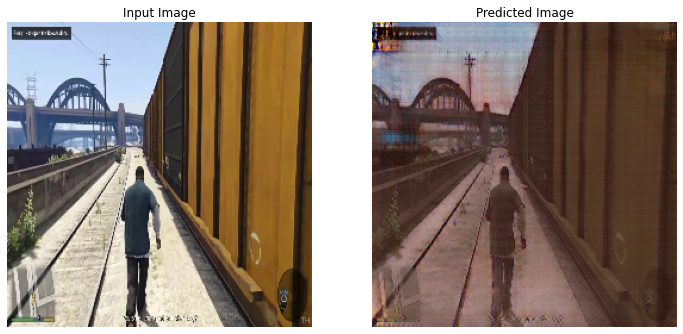
Here, we see some similar patterns as before. We notice that much of the shape, orientation of the original image is preserved, however, the colorscheme and brightness of the original image are modified to look like its counterpart.
I also attempted training for longer, but the model underwent mode collapse, as shown below:
GTA 3 -> 5


GTA 5 -> 3


These results seem to indicate that there is, in fact, some coarse details that can be effectively translated from GTA 3 to GTA 5 graphics, and vice-versa, however, fine details fail to be translated properly. Additionally, the process seems to be adding more artifacts that degrade overall image quality. At this point, it may be worth performing some sort of hyper-parameter/neural architecture search in order to determine the impact of different parameters and models on learning dynamics. Additionally, the authors of CycleGAN have released a new paper and corresponding GitHub page discussing a more sophsiticated image to image translation technique, known as Constrastive Learning, that both improves the quality of produced images and reduces the overall training time. This may be worth looking into as well. Finally, one cause for concern is the data itself. Image to image translation, for the purposes being used here, is known to struggle when the gaps between the two domains are very large. Large gaps correspond to domains that share very little similarities. For example, horse2zebra both involve morphing the colors of objects that share similar sizes and shapes. This makes it easier for CycleGAN to perform object localization. However, even in these certain instances, it still becomes difficult to isolate the “horse” and “zebra” as is shown in this example:

This failure of isolating certain objects that need to be transformed is a limitation of CycleGAN. With this in mind, there are a few ways in which the existing methodology can be improved in order to get better results:
- Isolate similar images from both domains.
- This would reduce the gap between the domains. It is clear that GTA 5 has many backgrounds, close-ups, and scenes that are very different from GTA 3. These shots likely make it difficult for the model to effectively generalize between the domains. One potential fix here would be to isolate similar images from each domain in order to make the trasfer of content between domains easier. For example, if all of the driving screenshots were isolated from both GTA 3 to GTA 5, it may be easier to translate between the domains, since each of the domains are more specefic and share more similarities with each other.
- Use less images between the domains
- It seems apparent that the model is prone to overfitting, as is exhibited by the mode collapse when training for 1000 epochs. Due to the high variance between the two domains, it may be easier to learn a mapping between domains if there are just less images in total. This may provide better results on the training dataset, but may hurt generalization capabilites in the long run.
- Explore different hyper-parameters and model architectures.
- As stated above, the architecture and hyper-parameters used here were predefined from this Tensorflow blog post. It is possible that these same parameters will not work well with this particular dataset. A small architecture/hyper-parameter search may show promising results.